Technology Transfer Network / NAAQS
Ozone Implementation
Spatial Clustering of Ambient Ozone
in Eastern U.S.
|
By William M. Cox
Air Quality Modeling Group Emissions, Monitoring and Analyses Division Office of Air Quality Planning and Standards US Environmental Protection Agency
DRAFT
January 1997
Ambient ozone data from AIRS data were used to perform a simple analysis of the spatial correlation structure of daily maximum 8-hour ozone levels. The purpose of the analysis was to determine the extent to which covariation among several hundred monitoring stations could be summarized by a small number of clusters (4 to 12) and to determine how these clusters appear geographically. The data used in this analysis were taken from AIRS for all monitoring stations east of the 100th longitude from June through September of 1991 through 1995. Daily maximum 8-hour averages were computed as the highest of the 17 running 8-hour periods beginning with the period from hour 1 through hour 8 and ending with the period from hour 17 through hour 24. The ozone data were aggregated up to the county level by averaging daily maximum 8-hour values within counties having multiple monitors.
The resulting data base was further restricted by eliminating counties that did not have at least 300 days of data (approximately half of 5 yrs x 122 days per year). Because the clustering technique permits no missing data, the county average was substituted in place of days having no reported ozone values. This substitution also has the desired effect of de-emphasizing counties that have less than complete (610 days) of data for the analysis. The resulting data matrix used as input to the clustering routine consisted of 610 daily observation by 429 counties spread out (unevenly) over the eastern part of the U.S.
|
|
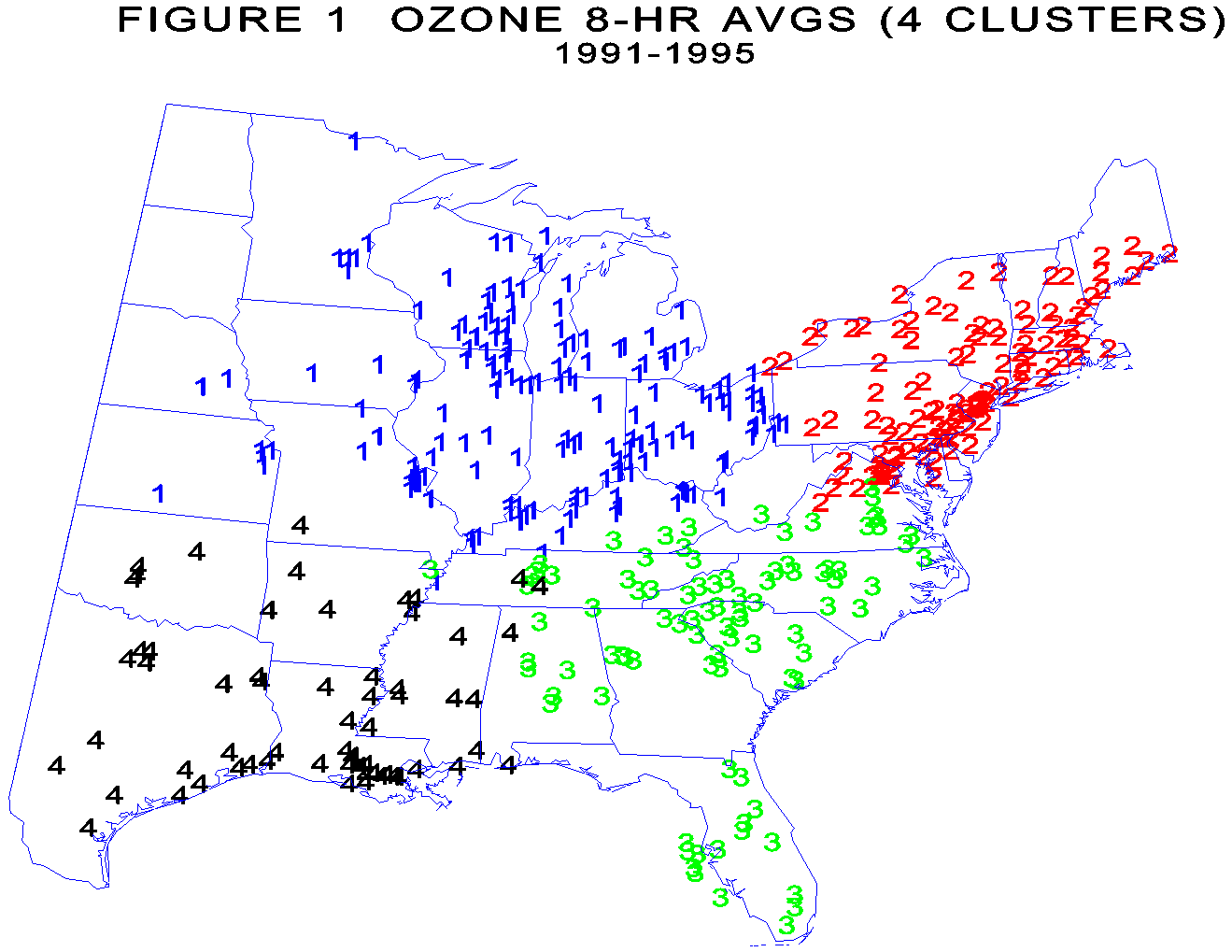
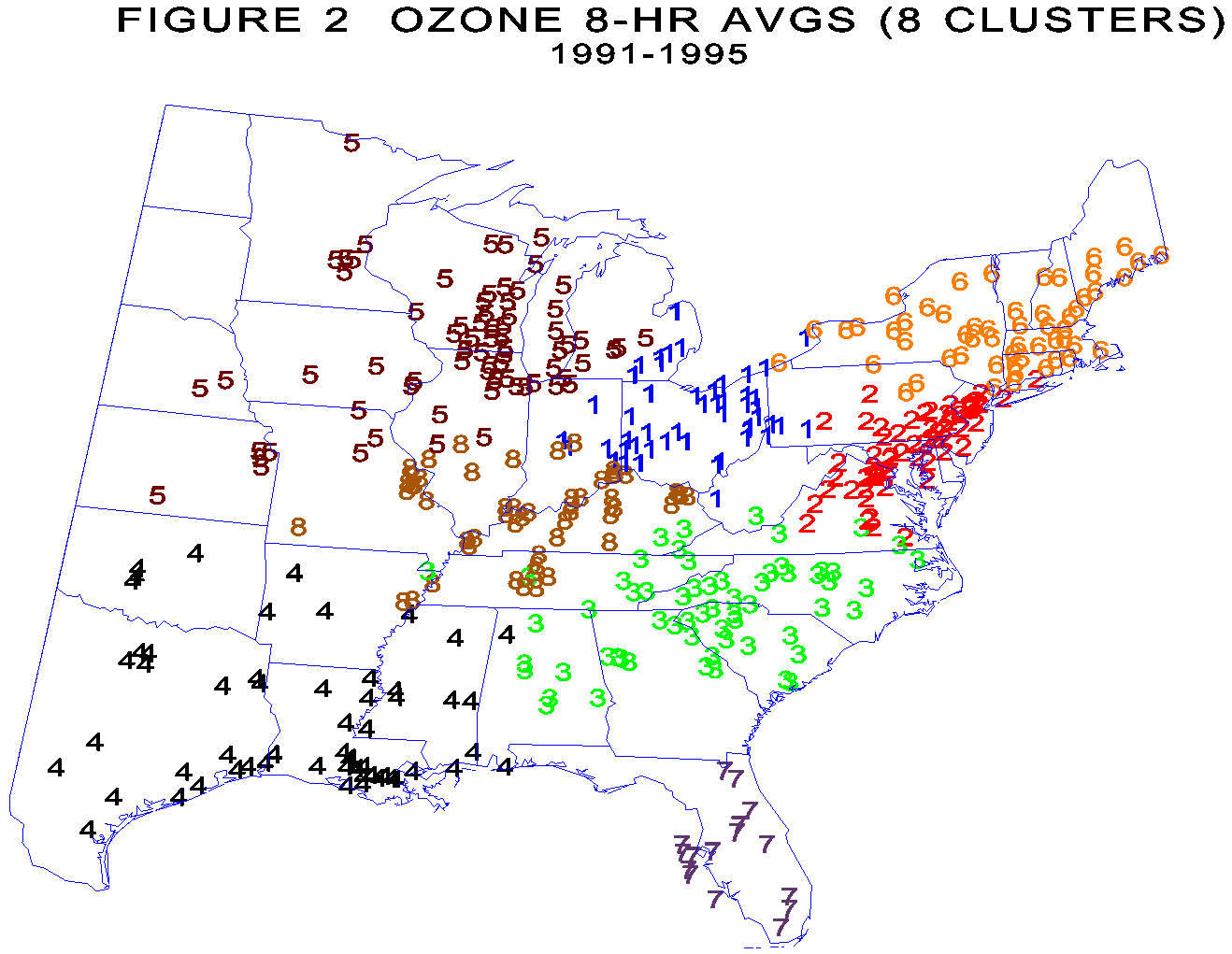
The SAS procedure VARCLUS was used for the analysis. The number of clusters was arbitrarily limited to range from 4 up to a maximum of 12 to conserve computer time. Figure 1 shows the four cluster result which essentially divides the eastern US into four quadrants corresponding to the Northeast (2's), Midwest (1's), Southeast (3's) and Southwest (4's). These four clusters explain approximately 51 percent of the day-to-day variation among the 429 counties. Figure 2 shows the results for eight clusters. The northeast cluster has split into two clusters (New England and North Atlantic), the southeast into two clusters (southeast mainland and Florida). The Midwest split twice, first by splitting of the most westerly portion (5's) and last by splitting Kentucky and Tennessee (8's) from Ohio, West Va and part of Pennsylvania (1's). The total variance explained by 8 clusters is approximately 60 percent of the total variance. Further splits are possible but may or may not be meaningful or interpretable. |